The nature of the cloud and the nature of the applications that enterprises are choosing to run in the cloud require that Observability solutions be used to make sure that these applications are delivering the appropriate levels of reliability and performance to their constituents.
What is Observability?
For a complete discussion of what Observability is and how it is different from monitoring, please see “What is Observability and How to Implement It“. The short answer is that Observability means the following:
- You know what the unit of work is (transaction, call, trace, etc.) that the business cares about
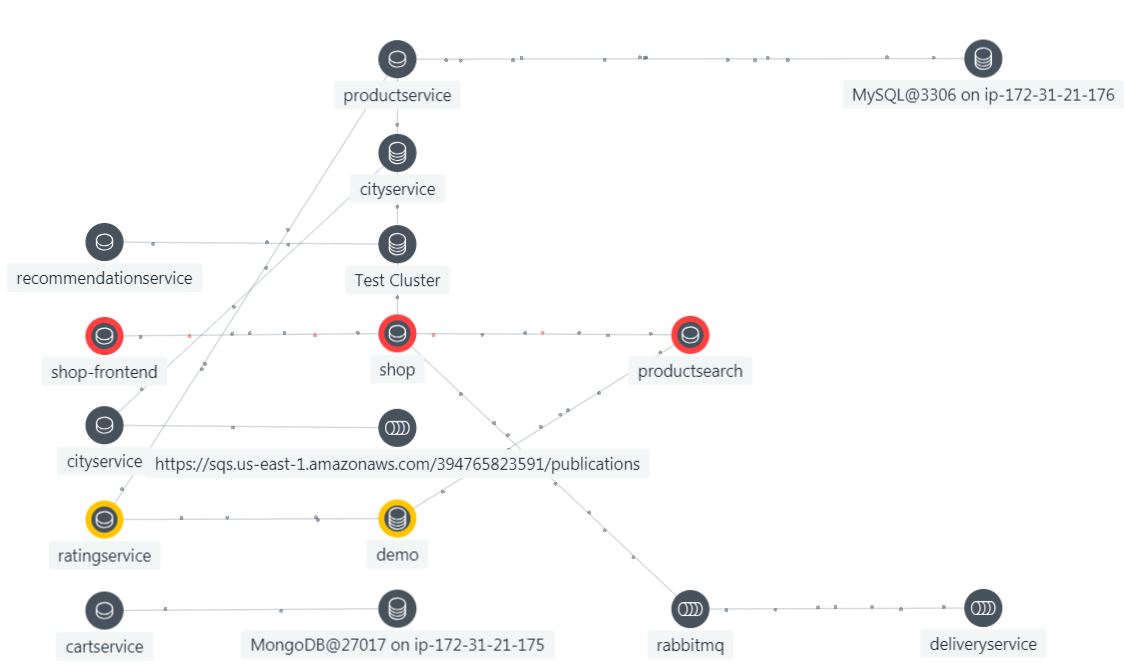
- For every unit of work, you collect every trace, span, log, set of metrics (performance (latency), throughput (calls per second) error rate, and contention, code profiles, topology, dependencies and configuration information for the entire stack of supporting software for that unit of work.
- You apply high cardinality analytics to this massive stream of data in real time to find the exceptions that are worth paying attention to.
- You apply AI and ML across the topology and dependency maps for the anomalous units of work to find deterministically related anomalies that could be the root cause of the issue
What is the Nature of Cloud Based Applications?
Running applications in the cloud is a completely different endeavor than running them in dedicated on-premise infrastructure. The cloud and cloud based applications have the following unique characteristics:
- The cloud is itself dynamic. The “neighbors” (other peoples workloads) with which you are sharing resources is changing constantly. The composition of the resources allocated to your cloud image (the VM) or your service (in the case of a serverless transaction) may be changing due to actions taken by your cloud provider.
- The applications that you chose to run in the cloud are likely very important to your business. You would likely not choose to run them in an environment where you had to pay to run them via a consumption based model if they were not important. If an application is not important, you would most likely choose to run it on some fully depreciated hardware in you own or a co-located data center.
- Since the applications that you are running in the cloud are important (they are most likely part of your Digital Transformation Initiatives), you are likely enhancing them with a CI/CD process. That means you your application teams are updating the application frequently – potentially hundreds or even thousands of times a day.
- The software stack that supports your application in the cloud is extremely complex, and itself constantly changing as your developers choose to rely upon different services to enhance the applications
- The operation of the applications and their containers can be highly dynamic itself – orchestrated by Kubernetes or a Kubernetes service from your cloud provider.
So in summary, cloud based applications are changing rapidly, are very complex and are subject to automated dynamic changes by orchestration software like Kubernetes. The combination of applications with these characteristics running in dynamic cloud environments requires Observability for the following reasons:
- When the rate of change across the cloud infrastructure and the application stack is this high, having monitoring software that samples either or both the application and the infrastructure once a minute is no longer good enough. Too many bad things can happen in between those one minute samples. Observability means comprehensive instrumentation, and comprehensive instrumentation is required for highly dynamic applications and systems.
- Just knowing the logs, traces, spans and associated metrics for every call is not good enough. When something goes wrong you need code profiles, the complete topology map, dependency map, and set of associated configuration data (and what changed) to have a chance at resolving the issue quickly and correctly.
- AI, ML and AIOps are worse than useless unless they have true Observability data (comprehensive data with related topologies and dependencies over time) as their foundation. Otherwise you fall into the trap of confusing correlation with causation which is itself the cause of an enormous amount of wasted time and toil.
If you want to understand how the monitoring vendors are doing in their transition to Observability, please read “Ranking the Observability Offerings“. The table in this article is kept up to date as the products evolve.